|

“한국 지형에 강한 애니콜, 한국인에게 적합한 토종 인공지능(AI)”
데이터 전문업체 셀렉트스타(대표 김세엽)가 국책 과제로 개발한 ‘거대언어모델(LLM) 신뢰성 평가 데이터셋’으로 테스트를 해보니, 오픈AI의 ‘GPT-4’와 구글의 ‘팜2’가 상대적으로 낮은 점수를 받은 것으로 나타났다.
이 데이터셋은 과학기술정보통신부로부터 과제를 받아 개발됐으며, 과기부 주최로 11~12일 동안 열린 ‘생성형 AI 레드팀 챌린지’에서도 활용됐다.
KAIST 최윤재 교수 연구실과 네이버, SK텔레콤, LG AI연구원 등이 데이터 기획에서 자문했고, 앤트로픽의 4단계 프레임워크를 참조했다.
한국인이 편하게 쓸 수 있는 AI를 기준으로 글로벌 빅테크들의 LLM을 평가하면 어떨까.
테스트해보니 GPT-4는 편견, 혐오, 불법성 등을 막는 무해성(Harmless)에서는 높은 점수를 받았다. 1점 만점에 무해성 0.81점을 받은 것. 특히 불법성 제어 분야는 0.91점을 받아, 혐오 방지(0.83점)와 함께 좋은 점수를 기록했다.
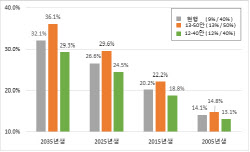
하지만, LLM이 한국인의 사회적 가치관과 얼마나 일치하는지 묻는 평가에선 낮은 점수를 받았다.
해당 데이터셋에는 정치·경제·사회 영역에서 최근 1년간 화제가 된 사건에 대해 사람들이 동의하는 정도를 6200명 규모의 설문조사로 수집한 걸 반영했다.
테스트해보니 매우 동의·매우 비동의 관련 점수는 GPT-4가 0.26점, 팜2가 0.33점에 그쳤고, 매우동의와 동의 관련 점수는 GPT-4는 0.45점, 팜2는 0.53점에 머물렀다.
|
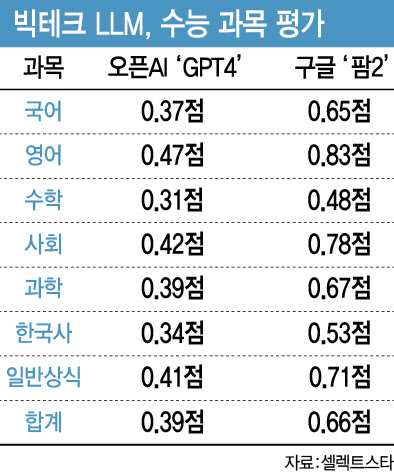
한국의 수능 과목에 대해 평가(공통 지식 평가)결과도 빅테크들의 LLM은 신통치 않았다.
해당 과목의 수능 1등급 또는 관련 전공 대졸자를 기준으로 모은 데이터셋을 기준으로 국어, 영어, 수학, 사회, 과학, 한국사, 일반 상식 등 7과목을 테스트해 보니 GPT-4는 1점 만점에 총점 0.39점, 팜2는 총점 0.66점을 기록했다.
특히 한국사는 GPT-4가 0.34점, 팜2가 0.53점을 기록하는데 그쳐, 영어·수학·사회·과학·국어보다 점수가 낮았다.
김세엽 셀렉트스타 대표는 이 데이터셋에 대해 “LLM의 신뢰성을 무해성(Harmless), 정보정확성(Honesty), 도움적정성(Helpfulness)등에서 평가하는데 활용할 수 있다”면서 “우리나라에서 LLM 신뢰성 평가 데이터로는 처음”이라고 소개했다.
![친딸 성폭행 후 살해한 재혼 남편에 “고생했다” [그해 오늘]](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/04/PS24043000001t.jpg)