


|

최근 도널드 트럼프 대통령의 지침에 따라 미 재무부를 비롯한 각국 정부와 금융당국은 미토스와 같은 고성능 AI 모델이 국가 안보에 미칠 위협을 평가하며 긴급 대응책 마련에 나섰다. 특히 미 재무부는 앤트로픽 모델의 사용 중단 지침을 내리는 한편, 미토스에 대한 별도의 접속 권한을 얻기 위한 협의를 진행하는 등 강력한 리스크 관리 행보를 보였다. 이러한 압박 속에서 앤트로픽은 “정부는 AI의 국가 안보 위협을 완화해야 하며, 이를 위해 연방 정부 등과 협력할 준비가 돼 있다”는 입장을 밝히며 오퍼스 4.7을 그 해결책으로 제시했다.
앤트로픽은 오퍼스 4.7에 대해 전작인 오퍼스 4.6을 직접적으로 업그레이드한 버전으로, 특히 고난도 소프트웨어 엔지니어링과 비전 기능, 전문 업무 수행 능력에서 비약적인 발전을 이뤄냈다고 설명했다.
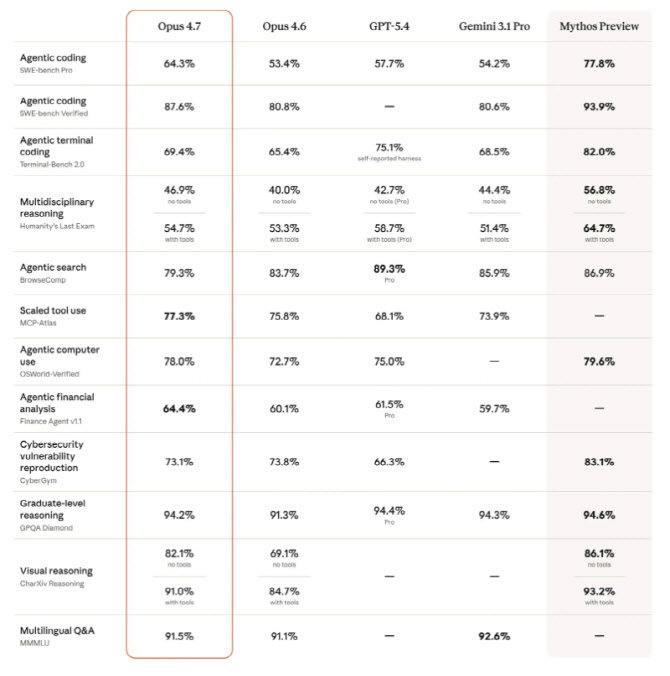
가장 눈에 띄는 변화는 자율적인 코딩 능력의 강화다. 오퍼스 4.7은 스스로 논리적 결함을 파악하고 실행을 가속화하며, 복잡하고 긴 시간이 소요되는 작업을 일관성 있게 처리한다. 인튜이트(Intuit)는 “오퍼스 4.7이 계획 단계에서 스스로 논리적 결함을 잡아내고 실행을 가속화한다”고 평가했으며, 볼트(Bolt. new)는 “앱 구축 작업에서 성능이 최대 10% 향상되면서도 기존 에이전트 모델의 고질적 문제인 성능 퇴보가 없었다”고 밝혔다. 벤치마크 결과, 에이전트 코딩 성능을 측정하는 ‘SWE-bench Pro’에서 64.3%를 기록해 GPT-5.4(57.7%)와 제미나이 3.1 프로(54.2%) 등 비교군 모델들을 앞질렀다.
시각 정보 처리 능력인 비전(Vision) 기능도 대폭 개선됐다. 이전 모델보다 3배 이상 높은 최대 375만 화소(2576 픽셀)의 고해상도 이미지를 지원하며, 이를 통해 복잡한 기술 도표 해석이나 정밀한 스크린샷 분석이 가능해졌다. 실제 엑스보우(XBOW)의 시각적 예민도(visual-acuity) 테스트에서는 오퍼스 4.6(54.5%)을 크게 웃도는 98.5%의 점수를 기록했다. 솔브(Solve)는 이 기능을 활용해 생명과학 분야의 특허 워크플로우를 구축하고 있다.
전문 지식 업무에서도 일반 공개 모델 중 최고 수준의 성능을 입증했다. 경제적 가치가 있는 지식 업무를 평가하는 ‘GDPval-AA’에서 1753점을 기록해 GPT-5.4(1674점)와 제미나이 3.1 프로(1314점)를 제치고 상위권에 올랐다. 헥스(Hex)는 “데이터가 누락되었을 때 거짓 답변을 내놓는 대신 정확히 보고하며, 오퍼스 4.6조차 빠졌던 데이터 함정들을 이겨낸다”고 극찬했다. 데이터브릭스(Databricks)는 오퍼스 4.7이 문서 질의응답 테스트인 ‘OfficeQA Pro’에서 전작 대비 오류를 21% 줄였다고 분석했다.
|
앤트로픽의 이고르 오스트로브스키(Igor Ostrovsky) 최고기술책임자(CTO)는 “앤트로픽은 이미 코딩 모델의 표준을 세웠으며, 클로드 오퍼스 4.7은 시장에서 가장 최첨단 모델로서 그 표준을 한 단계 더 의미 있게 밀어붙였다”며 “사용자의 의견에 단순히 동의하기보다 문제에 대해 깊이 고민하고 주관 있는 관점을 제시한다”고 밝혔다.
이용 가격은 기존과 동일하게 입력 토큰 100만 개당 5달러, 출력 토큰 100만 개당 25달러로 유지된다. 다만 새로운 토크나이저 도입으로 동일 입력에 대해 토큰 사용량이 1.0~1.35배 늘어날 수 있다는 점은 주의가 필요하다. 현재 클로드 API, 아마존 베드록, 구글 클라우드 버텍스 AI, 마이크로소프트 파운드리를 통해 즉시 이용 가능하다.
세부 지표를 보면 오퍼스 4.7은 SWE-bench Pro(64.3%), SWE-bench Verified(87.6%)에서 최고 성능을 보였고, 금융 분석(64.4%)과 대학원 수준 추론(94.2%) 등에서도 전작을 상회했다. 반면 사이버 보안 취약점 복제(CyberGym) 테스트에서는 73.1%를 기록해, 공격 역량을 의도적으로 줄여 안전성을 확보하려는 설계 의도를 뒷받침했다.


![김병주 ‘개인보증' 수용…홈플러스 운명, 다시 메리츠 손에[only 이데일리]](https://image.edaily.co.kr/images/Photo/files/NP/S/2026/07/PS26070300789t.1200x.0.jpg)



